Logistic regression is used to classify instances based on the values of their predictor variables. The output is the probability that an input data item belongs to a certain class (compare the support vector machine, where the output is the single class that best fits the input data item).
Note that in situations where the predictor variables are known to be normally distributed (Gaussian distribution), discriminant analysis is normally expected to yield better results than logistic regression.
Binomial logistic regression
Binominal logistic regression is the simplest case where the classification is between two groups. It typically involves predicting whether a given feature will be present or absent (e.g. whether somebody will be employed during a given period) but even situations where the choice is between two positive choices (e.g. Trump vs Clinton) can be expressed in true / false terms with respect to either of the outcomes.
Using ordinary least-squares regression (OLSR) with the dependent variable captured in the training data as 1 to represent “true” and 0 to represent “false” would produce a function that would estimate the probability of new data falling into the “true” category. This would capture the general idea, but in practice several problems would occur:
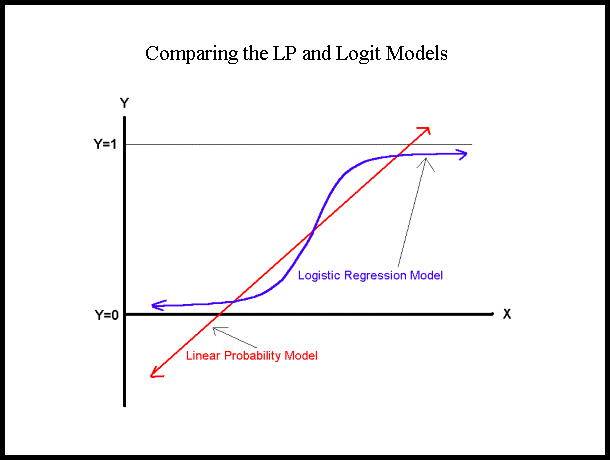
- The resulting function might generate values outside the range 0 ≤ x ≤ 1.
- Because the training data would all have one of two values of the dependent variable but the resulting function would be linear, it would necessarily be wildly heteroscedastic, thus violating prerequisite 6 for OLSR.
- A straight line does not correspond to probability distributions observed in the real world.
For these reasons, logistic distribution uses either logit or a probit function to yield function curves that look similar to how real probabilities actually behave (see this diagram within this excellent introduction). The differences between logit and probit curves are only of relevance to advanced statisticians. For our purposes using logistic regression for normal business purposes, we can regard them as equivalent.
{kind=link}
For a binominal logistic distribution, a common (although controversial) rule of thumb to determine whether training data is sufficient to yield a working model is to take the number of training items that lead to the less frequently occurring of the two possible outcomes and divide this number by 10. If the number that results is greater than the number of predictor variables, the training data should suffice (rule of ten).
Note that logistic regression, unlike ordinary least-squares regression, has to be solved iteratively; there is no analytic solution.
Multinomial logistic regression (also: Conditional maximum entropy model, Maximum entropy classifier, MaxEnt model)
Multinomial logistic regression covers the case where items are classified into one of three or more mutually exclusive categories. The algorithms can be broadly understood as calculating the probability function for each category using a separate binominal logistic regression and then combining the functions to form a single model, although there are actually several mathematically more efficient ways of achieving the same thing.
Ordinal logistic regression
In ordinal logistic regression, the categories are ordered so that membership in a category implies simultaneous membership of all categories lower down the scale. An example would be modelling education level where the categories are: primary-level school education; secondary-level school education; undergraduate-level university education and graduate-level university education.
Mathematically, the procedure is essentially the same as for multinomial logistic regression, the main difference lying in the structure of the input data.
Nested logistic regression
Provided that appropriate care is taken to challenge any assumptions, it can be helpful to nest regression steps to reflect obvious structures within the choices being modelled. For example, if the aim is to predict whether a consumer will choose to eat beef, pork, salad or lentils, it might make sense to start with a dichotomy into meat / non-meat to capture the fact that only two of the choices are relevant to vegetarians.
- alias
- subtype
- Logit regression Probit regression Binomial logistic regression Multinomial logistic regression Ordinal logistic regression Nested logistic regression Conditional maximum entropy model Maximum entropy classifier MaxEnt model
- has functional building block
- FBB_Classification
- has input data type
- IDT_Vector of quantitative variables
- has internal model
- INM_Function
- has output data type
- ODT_Probability ODT_Classification
- has learning style
- LST_Supervised
- has parametricity
- PRM_Parametric
- has relevance
- REL_Relevant
- uses
- ALG_Least Squares Regression
- sometimes supports
- mathematically similar to
- ALG_Markov random field